En 2007, un internaute a découvert une directive "Noindex" non documentée mais supportée par Google. Ce "Noindex" dans le fichier robots.txt permet d'avoir le même effet que la balise meta robots noindex, c'est-à-dire interdire l'indexation d'un document.
Dans cet article de 2007, un employé de Google a confirmé que le robot Googlebot comprenait et suivait cette directive mais que cela n'était pas gravé dans le marbre et qu'aucun support et annonce officielle n'a été fait sur ce sujet.
Cette directive s'implémente de la même manière que la directive Disallow, Allow ou Sitemap. Si vous souhaitez empêcher l'exploration d'un document, le robots.txt est écrit de cette façon :
User-agent: *
Disallow: /page-a.htmlSi vous souhaitez bloquer l'exploration et l'indexation de la page, nous faisons appel à la directive Noindex :
User-agent: *
Disallow: /page-a.html
Noindex: /page-a.htmlQuelques tests via les outils pour les webmasters de Google permettent de confirmer rapidement que cette directive "Noindex" fonctionne toujours et qu'elle accepte également les wildcards.
Robots.txt en place pour le test :
User-agent: *
Noindex: /page-a.html
Noindex: /article-*URL testées :
https://robots-txt.com/page-a.html
https://robots-txt.com/article-a.htmlRésultats, les deux pages sont bien annoncées comme bloquées par Google :
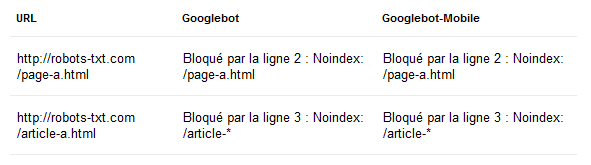
Source : "Q&A: An undocumented robots.txt crawler directive from Google"